Artigo
DRM Xe e o pesadelo computacional
Este texto nasce como uma nota de investigação. Ainda estou aprendendo sobre o DRM Xe, então prefiro publicar o processo enquanto ele acontece em vez de esperar um texto definitivo.
Sempre tive interesse em entender as entranhas do software, mas esse tipo de curiosidade exige tempo além da vontade. No ano passado, comprei um Asus Zenbook S14 para trabalho, equipado com um Intel Core Ultra 7 258V e 32 GB de RAM integrados. Como a máquina veio com Windows 11, logo fiz o dual boot com Fedora para acompanhar de perto as atualizações de kernel e drivers.
A paz durou pouco: em uso pesado de CPU, o laptop congelava completamente, exigindo reinicializações forçadas. Foi esse incômodo que me empurrou para o baixo nível. O que começou como uma busca pela causa dos travamentos logo se tornou algo mais interessante: entender como o hardware recente e o software se encontram no kernel e, quem sabe, como contribuir para o amadurecimento dessa plataforma.
Nesse caminho, encontrei o DRM Xe, o Direct Rendering Manager mais novo da Intel. Ele é o sucessor do i915 nas arquiteturas recentes e deve concentrar o suporte às próximas gerações de GPU da Intel no Linux. Embora o desenvolvimento tenha começado em 2021, ele já se mostra um driver maduro, construído por engenheiros da Intel que contribuem ativamente no ecossistema Open Source.
Mergulhar no Xe me fez perceber que gerenciar uma iGPU (integrada) moderna impõe desafios imensos, especialmente no gerenciamento de memória e nos estados de energia (D-states). Diferente do i915, que carregava anos de “legado”, o Xe propõe uma base de código limpa, mas que introduz abstrações complexas como o GuC (Graphics Microcontroller) e o HuC.
O GuC, inclusive, é um universo à parte que eu sequer sabia que existia. Ele é um microcontrolador integrado ao SoC responsável por orquestrar a submissão de comandos e o escalonamento (scheduling) da GPU. Para isso, ele utiliza o GGTT (Global Graphics Translation Table), uma tabela que permite ao microcontrolador mapear e acessar a memória RAM do sistema. A maior surpresa, porém, foi descobrir que alguns GuC utilizam arquiteturas ARM ou RISC-V. Faz total sentido: são arquiteturas muito mais eficientes energeticamente para essa função do que o x86 seria.
Essa descoberta de que existe “um computador dentro do computador” gerenciando recursos fez várias perguntas borbulharem na minha mente:
1. Se os processos de usuário usam a GPU, quem controla a memória (VRAM) usada por eles?
R: O próprio driver. Ele mantém estruturas internas e espaços de endereçamento virtual que garantem o isolamento entre contextos. O driver sabe exatamente quem é o “dono” de cada alocação para garantir que um processo não acesse os dados de outro, mas ele é agnóstico ao conteúdo, para o driver, pouco importa se aqueles bits são uma textura ou um cálculo matemático.
2. E como o driver usa a DRAM de forma compartilhada para criar uma VRAM?
R: Em GPUs integradas, utilizamos a UMA (Unified Memory Architecture). Existe um complexo sistema de mapeamento para que a GPU enxergue partes da memória RAM do sistema como se fosse sua própria memória local. Esse mapeamento dinâmico é um tema denso que pretendo detalhar nos próximos posts.
3. Como a interface de um programa é transformada em pixels na tela?
R: Este é um ponto que ainda estou estudando a fundo, mas envolve recursos herdados e compartilhados com o i915. O driver é responsável por gerenciar os BOs (Buffer Objects), pedaços de memória contendo os dados brutos, e orquestrar sua exibição através do KMS (Kernel Mode Setting), controlando qual monitor atualizar e com qual frequência.
Responder a essas dúvidas me levou a outra conclusão: se existem mapeamentos para processos, existem contextos de execução. E quem controla a troca desses contextos a nível de software é, novamente, o driver.
Para visualizar melhor onde o DRM Xe se encaixa nesse fluxo, desenhei este macro-pipeline:
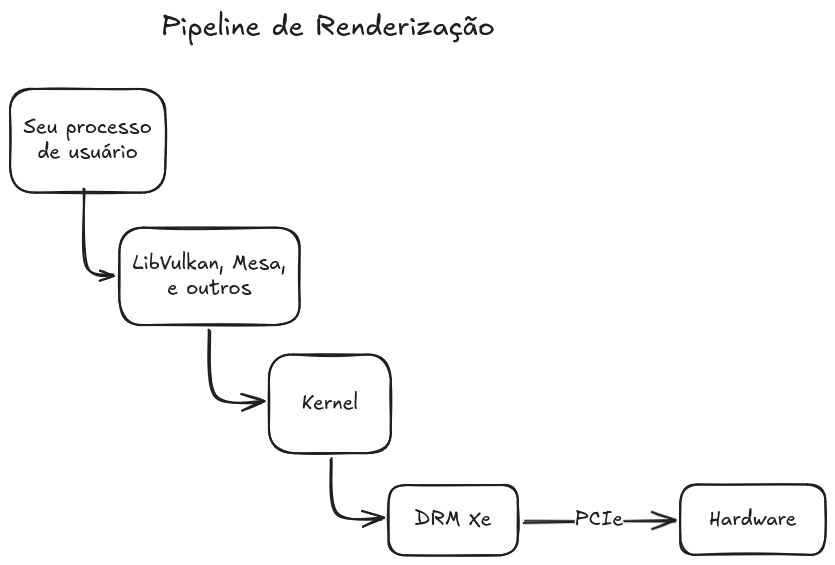
Curiosamente, embora o sistema enxergue a iGPU como um dispositivo PCI, no Lunar Lake essa comunicação ignora os fios físicos do PCIe e corre por uma malha de silício interna (Fabric), o que explica por que um bug aqui derruba o sistema tão rápido: estamos compartilhando a mesma estrada principal de dados da CPU.
É importante lembrar que esse papel de “gerente de recursos” do driver é vital não só para vídeo, mas para o multiprocessamento via kernels de GPU, recurso essencial para modelos de Machine Learning, por exemplo.
O caminho para a contribuição
Mas como se entra nesse jogo? Descobri que o desenvolvimento para novos contribuintes acontece em um ramo (branch) focado em integração: o drm-tip. Embora existam processos internos que mantêm o kernel principal em paridade com esse ramo, é no drm-tip que as novas funcionalidades são validadas.
Os próprios engenheiros da Intel analisam os patches e sugerem melhorias. Para garantir a estabilidade, existe uma suíte de testes gigantesca (como o IGT GPU Tools) e um repositório para execução de live tests automatizados em hardware real, validando cada alteração antes mesmo de ela ser fundida ao código principal.
Sei que este é apenas o primeiro post e que ainda falta muita coisa para ser explicada. A minha maior dor agora é justamente essa vastidão de detalhes, mas a meta é clara: documentar tudo até conseguir lançar meu primeiro patch no DRM.
Me acompanhem nessa jornada.
Discussão